
Lịch sử tương tác người máy
Trong vòng 75 năm vừa qua, cứ khoảng một thập niên thì có những phát minh mang tính đột phá trong lĩnh vực này; ví dụ: GUI vào năm 1981, máy tính cầm tay (PalmPilot) vào những năm 90, năm 2007 iPhone đưa ra giao diện bấm chạm (touch). Gần đây nhất là giao diện giọng nói (Voice Interface) bắt đầu được sử dụng rộng rãi sau khi Apple giới thiệu hệ thống Siri trên iPhone.
 |
| Figure 1 - Lịch sử tương tác người-máy (1830s- 2015) |
Tại sao bây giờ?
Thực ra giao diện giọng nói đã được nghiên cứu và phát triển đã lâu, ví dụ trong quảng cáo của Apple năm 1987 đã đưa ra viễn cảnh người và máy có thể tương tác qua giọng nói như hội thoại bình thường. Tuy vậy, công nghệ nhận dạng giọng nói (speech recognition) và công nghệ sử lý ngôn ngữ tự nhiên (Natural Language Processing) không đủ tốt để hiện thực hóa và đưa vào thực tiễn hàng ngày một hệ thống giao diện giọng nói.
Tuy vậy, bắt đầu từ khoảng năm 2010-2011 đã có những đột phá trong các công nghệ giọng nói. Theo lời của Johan Schalkwyk, kỹ sư làm việc tại Google “Ba năm trước, công nghệ của Google chỉ nhận ra được 3 trong 4 từ mà bạn nói ra… bây giờ (2014), ứng dụng của Goolge có thể hiểu được 12 trong số 13 từ”.
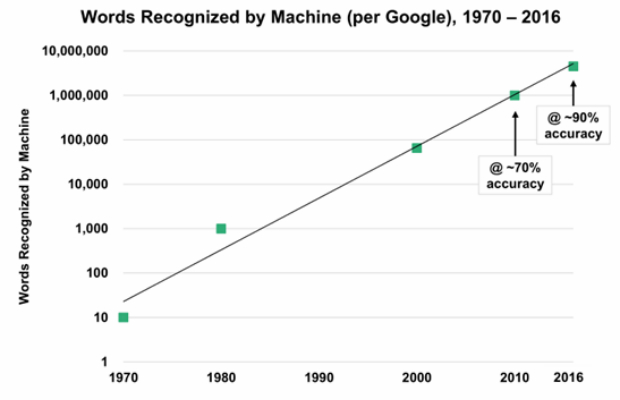 |
| Figure 2- Độ chính xác nhận dạng từ trong môi trường ít tiếng ồn (theo Google) |
Có thể nói công nghệ nhận dạng tiếng nói đã bắt đầu đạt ngưỡng đủ tốt để người dùng chấp nhận, không chỉ trên nền tảng của Goolge, mà các hãng công nghệ (và nền tảng của họ) đều đã đạt đươc ngưỡng nhận dạng từ (Word Accuracy Rates) chính xác hơn 90%.
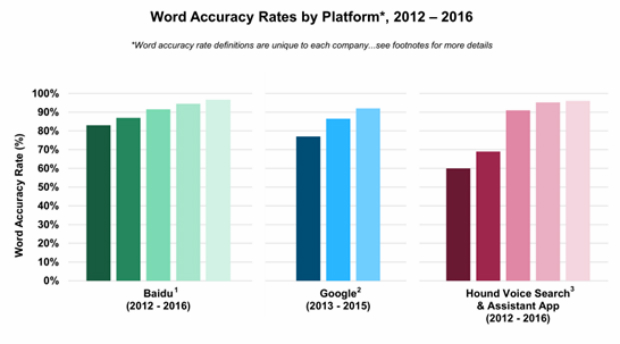 |
| Figure 3- Các công ty có thể định nghĩa về độ chính xác khác nhau |
Theo giáo sư Andrew Ng tại trường Standord, một nhà nghiên cứu hàng đầu thế giới trong lĩnh vực học máy (machine learning, deep learning), thì hai yếu tố chính để việc sử dụng giao diện giọng nói thực sự bùng nổ là hệ thống đạt được độ chính xác trong việc nhân dạng và hiểu ngôn ngữ ở ngưỡng 99%, đồng thời giảm độ trễ (latency) trong việc phản hồi của hệ thống. Các hệ thống giao diện giọng nói đang gần tiến đến ngưỡng này, ví dụ như sản phẩm Amazon Echo, gần đây đã cải thiện được độ trễ từ lúc người dùng ra lệnh cho đến lúc Echo phản hồi từ khoảng 9 giây xuống còn 1,5 giây.
Tương tác giọng nói cho các thiết bị IoT
Giao diện giọng nói (Voice Interface) có thể ứng dụng trong rất nhiều tình huống, tuy vậy, đây là một phương thức rất phù hợp cho các thiết bị IoT, do những yếu tố sau.
Dễ dàng, tiện dụng: Giao diện giọng nói không cần người sử dụng phải bàn phím hay các thiết bị điều khiển cầm tay; phương thức này rất phù hợp để điểu khiển các thiết bị thông minh trong nhà như đèn, TV, quạt...
Chi phí rẻ và gọn nhẹ: Đa số công việc xử lý giọng nói được thực hiện trên hệ thống điện toán đám mây, nên về phía thiết bị chỉ phải trang bị microphone, loa, bộ xử lý cấp thấp. Các linh kiện này ngày càng rẻ do ăn theo dây chuyền sản xuất điện thoại (smartphone supply chain).
Nhanh: Trung bình một người có thể nói 150 từ trong một phút so với gõ được 40 từ qua bàn phím.
Hiểu được văn cảnh: Những tiến bộ gần đây trong lĩnh vực trí tuệ nhân tạo (AI) giúp cho hệ thống giao diện giọng nói có thể hiểu được câu hỏi dựa vào văn cảnh tương tác.
FPT chuẩn bị gì cho xu hướng công nghệ này?
Việc sử dụng giao diện giọng nói tăng đột biến trong 2 năm gần đây, theo báo cáo của Baidu thì dịch vụ nhận dạng tiếng Trung của Baidu tăng 4x từ Q2:14, dịch vụ tổng hợp tiếng Trung của họ tăng 26x. Đối với một số ngôn ngữ thì đây là hình thức tương tác ưu việt hơn bàn phím cho việc nhập liệu ngôn ngữ bằng bàn phím hoặc màn hình điện thoại khó khăn hơn nhiều so với các ngôn ngữ dùng bẳng chữ cái Latin.
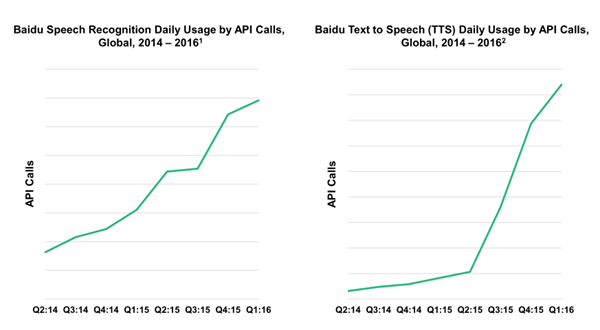 |
Tuy có nhiều ưu điểm như trên, để triển khai một hệ thống giao diện giọng nói đòi hỏi nhiều công nghệ liên quan như: công nghệ nhận dạng tiếng nói (Speech Recognition), Công nghệ Tổng hợp Tiếng nói (Text to Speech), Công nghệ Xử lý Ngôn ngữ (Phân tích cú pháp), Trí tuệ nhân tạo (AI), etc. FPT đã và đang đầu tư nghiên cứu vào những lĩnh vực này. Hiện nay, cộng đồng đã có thể sử dụng công nghệ tổng hợp giọng đọc tiếng Việt của Ban Công nghệ tập đoàn quan cổng OpenFPT.vn.
Open FPT là nhắm tới việc thúc đẩy việc chia sẻ, và kết nối các công nghệ và kết quả nghiên cứu của tập đoàn (và các công thành viên) ra ngoài cộng đồng. Cổng dịch vụ công nghệ OpenFPT là một thành tố chính trong chương trình. Thông qua cổng này, các công nghệ trong tập đoàn FPT sẽ được mở ra cho cộng đồng sử dụng dưới dạng API (web services). Các nhà phát triển và cộng đồng có thể khai thác, sáng tạo ra các dịch vụ cho người dùng mà chính FPT cũng không nghĩ tới và làm được. Dù bạn là công ty khởi nghiệp, hay doanh nghiệp, hoặc nhà phát triển độc lập, chúng tôi tin rằng bạn sẽ tìm được những dịch vụ hữu ích từ OpenFPT.
Từ này đến cuối năm 2016, FPT sẽ tiếp tục ra mắt một bộ APIs cho các công nghệ phục vụ cho việc triển khai Giao diện Giọng nói.
Trần Tuấn Anh
(Bài viết trên TechInsigh)
(Bài viết sử dụng dữ liệu từ Báo cáo http://www.kpcb.com/blog/2016-internet-trends-report)









Ý kiến
()