
Nói đến Big Data, không thể không nhắc tới Apache Hadoop - một framework giúp những nhà phát triển xây dựng được các ứng dụng cũng như hệ thống phân tán. Khởi đầu của Hadoop là nơi lưu trữ dữ liệu với độ tin cậy cao kết hợp với khả năng xử lý hàng loạt dựa trên framework MapReduce -một framework có khả năng mở rộng và tính toán song song, giờ đây Hadoop còn được bổ sung thêm một số thành phần có khả năng xử lý thời gian thực, xử lý văn bản và hỗ trợ công cụ tìm kiếm như Impala hay Apache Solr.
Việc xây dựng hệ thống với Hadoop càng ngày càng trở nên dễ dàng, với thao tác đơn giản là cài đặt CDH là mọi thành phần trong hệ sinh thái của Hadoop đều đã sẵn sàng. Tuy nhiên, cụ thể của việc thiết kế, xây dựng hệ thống này như thế nào vẫn luôn là câu hỏi lớn cho các chuyên gia công nghệ. Với số lượng ứng dụng được xây dựng trên Big Data hết sức phong phú, một trong những đề tài có sức hút lớn chính là: Kiến trúc Big Data.
Kiến trúc Big Data
Kiến trúc Big Data được xây dựng dựa trên một tập hợp các kỹ năng có thể giúp phát triển một luồng xử lý dữ liệu đáng tin cậy, có khả năng mở rộng và tự động hóa. Để có tập hợp các kỹ năng đó đòi hỏi phải có kiến thức nhất định về từng thành phần của hệ thống, từ việc thiết kế các cụm phần cứng cho đến việc thiết lập cài đặt cho toàn bộ quá trình xử lý của Hadoop. Sơ đồ dưới đây mô tả một cách khái quát về một hệ thống như vậy:
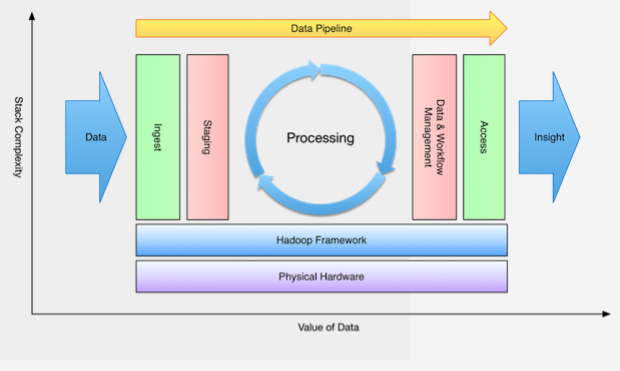 |
Từ sơ đồ trên có thể thấy luồng xử lý chính của hệ thống sẽ tiếp nhận đầu vào là dữ liệu thô và trả về những dữ liệu có giá trị. Xuyên suốt quá trình đó, những kỹ sư Big Data sẽ là người lựa chọn những công nghệ sử dụng bên trong; lựa chọn cách dữ liệu được lưu trữ, được truy xuất từ bên trong, bên ngoài; cũng như lựa chọn công cụ để xử lý dữ liệu đó… Như vậy có thể hiểu rằng những kỹ sư Big Data chính là những người thiết kế và triển khai kiến trúc Big Data.
Tiếp theo, chúng ta sẽ đi vào từng phần chính trong hệ thống bên trên để xem vai trò của chúng trong việc xây dựng luồng xử lý dữ liệu là gì.
Xây dựng cụm phần cứng
Xây dựng cụm phần cứng là một vấn đề phức tạp, khi mà việc thiết kế thường được thực hiện sau khi đã xác định được yêu cầu bài toán, mà ban đầu yêu cầu thường chưa rõ ràng. Hầu hết các nhà cung cấp dịch vụ đều có hướng dẫn cụ thể về việc lựa chọn phần cứng sao cho hợp lý nhất. Thông thường, một cụm phần cứng được khuyến nghị sẽ có 2 CPU với 4 đến 8 lõi cho mỗi CPU, ít nhất 48GB cho đến 512GB RAM cho việc lưu trữ dữ liệu tạm thời, ít nhất 6 cho đến 12 ổ cứng để lưu trữ những dữ liệu về thiết lập… Nếu vẫn còn gặp khó khăn khi xây dựng cụm phần cứng, ta luôn có thể thử xây dựng trước hệ thống bằng những dịch vụ trên cloud cho đến khi xác định rõ được yêu cầu bài toán.
Truyền tải
Sau khi có được cụm phần cứng thỏa mãn yêu cầu, điều tiếp theo cần quyết định là dữ liệu sẽ được truyền tải bằng cách nào. Trên thực tế có hai phương pháp chủ yếu để giải quyết bài toán này là truyền tải hàng loạt (batch ingest) và truyền tải theo event (event ingest). Phương pháp đầu tiên thích hợp cho dữ liệu dạng file và dữ liệu có cấu trúc, còn phương pháp sau thì thích hợp với các dữ liệu đòi hỏi xử lý thời gian thực như các dữ liệu về giao dịch hay logging.
Truyền tải hàng loạt
Khi truyền dữ liệu từ một nguồn dữ liệu có cấu trúc như RDBMS người ta thường lựa chọn Apache Sqoop. Sqoop hỗ trợ người dùng rất tốt trong việc chuyển dữ liệu từ RDBMS sang Hadoop, từ chuyển một phần cho đến chuyển toàn bộ. Sqoop sử dụng framework MapReduce và tích hợp các thành phần của JDBC trong nhiều hệ cơ sở dữ liệu phổ biến.
Có một phương pháp truyền tải hàng loạt khác phức tạp hơn đó là sử dụng file. Có khá nhiều cách để thực hiện được phương pháp đó nhưng hầu như không được ai áp dụng. Vấn đề phức tạp nằm ở nơi lưu trữ file cũng như API cần sử dụng để tải file. Trên thực tế người ta thường sử dụng phương pháp truyền tải theo event để tránh được việc phải tải một lượng lớn file như vậy.
Truyền tải theo event
Đối với truyền tải dữ liệu theo event thì Apache Flume là một công cụ tốt, nó có các agent hỗ trợ việc truyền dữ liệu dạng event từ một hệ thống sang một hệ thống khác, có thể là HDFS, Spark hay HBase. Flume đã được thử nghiệm kỹ lưỡng trên các cụm phần cứng lớn và tỏ ra rất đáng tin cậy. Phần phức tạp của Flume là việc cấu hình các agent và cấu trúc của Flume một cách đúng đắn.
Lưu trữ
Khi dữ liệu đã được truyền tải tới nơi, vẫn còn một vấn đề cần phải quan tâm trước khi tính tới việc xử lý, đó là lưu trữ dữ liệu. Đây không chỉ là vấn đề lưu trữ dữ liệu ở đâu mà dữ liệu đó còn phải có định dạng thích hợp, có kích thước thích hợp và cần có quyền truy nhập thích hợp đối với dữ liệu đó.
Định dạng lưu trữ
Định dạng như thế nào là thích hợp phụ thuộc vào việc ứng dụng xử lý hàng loạt hay xử lý thời gian thực. Đối với xử lý hàng loạt, những định dạng file như SequenceFile hay Avro đều phổ biến và thích hợp. Đối với những ứng dụng thời gian thực, có một cái tên mới nổi gần đây là Apache Parquet, nó có cấu trúc tương tự như những cơ sở dữ liệu dạng bảng nhưng cho phép truy xuất và xử lý những tập dữ liệu kích thước lớn một cách rất hiệu quả.
Ngoài ra cũng cần quan tâm đến việc dữ liệu sẽ được xử lý như thế nào sau một khoảng thời gian nào đó. Nên có một cơ chế để có thể lưu trữ những dữ liệu cũ vào một khu vực khác hoặc với một định dạng khác ít tốn bộ nhớ hơn, nhằm tránh việc lãng phí tài nguyên hệ thống.
Phân vùng dữ liệu
Câu hỏi tiếp theo là những dữ liệu đó sẽ được phân vùng như thế nào và với kích thước ra sao? Hadoop hỗ trợ rất tốt việc quản lý một số lượng nhỏ các file có dung lượng lớn. Chính vì vậy, việc thiết kế ra một hệ thống mà tạo ra nhiều dữ liệu bé trong HDFS sẽ chỉ làm cho tốc độ hoạt động của NameNode trở nên chậm chạp. Tất nhiên, đây vẫn là một hướng đi có thể sử dụng được nhưng sẽ đòi hỏi phải thêm một bước trung gian có nhiệm vụ ghép các dữ liệu có kích thước nhỏ lại với nhau.
Trong HBase, quá trình phân vùng dữ liệu được thực hiện một cách ngầm định bằng việc chia dữ liệu vào những hàng liền kề nhau trong bảng và sắp xếp chúng theo khóa đã định trước. Còn đối với HDFS thì việc phân vùng phải được tính toán trước, bởi vậy bạn sẽ cần phân tích cấu trúc của một mẫu dữ liệu để quyết định xem phân vùng thế nào là hợp lý nhất. Kinh nghiệm chỉ ra rằng tốt nhất nên tránh việc tạo ra các file có kích thước nhỏ (lý do đã được nhắc đến ở trên). Cụ thể mỗi file nên có kích thước tối thiểu là 1GB hoặc thậm chí lớn hơn tùy thuộc vào bộ dữ liệu cần được phân vùng.
Điều khiển việc truy nhập
Việc cuối cùng cần quan tâm trong quá trình lưu trữ dữ liệu là thiết lập dữ liệu theo một cơ chế nào đó để nhiều tiến trình khác nhau có thể truy nhập được mà không làm ảnh hưởng đến các tiến trình còn lại cũng như tính an toàn của dữ liệu.
Việc này không chỉ đơn giản là mỗi tiến trình đọc từ thư mục này và ghi ra một thư mục khác. Nếu dữ liệu được chia sẻ truy cập cho nhiều bên liên quan thì bạn cần định nghĩa ra một sơ đồ điều khiển truy nhập một cách chặt chẽ để kiểm soát xem ai sẽ được truy cập vào dữ liệu nào. Có một cách để giải quyết vấn đề đó là tạo ra những thư mục có gắn nhãn thời gian đối với mỗi tiến trình riêng biệt, điều này sẽ đảm bảo mỗi tiến trình kể cả được thực hiện song song cũng không làm ảnh hưởng đến dữ liệu của tiến trình còn lại.
Xử lý dữ liệu
Sau khi dữ liệu đã được lưu trữ, bước tiếp theo của toàn bộ quá trình sẽ là tự động xử lý những dữ liệu đó.
Biến đổi dữ liệu
Việc biến đổi dữ liệu ở đây không có nghĩa là sẽ làm mất mát một phần nào của dữ liệu đó mà là tiến trình giúp cho hệ thống xử lý dữ liệu một cách có hiệu quả hơn. Ví dụ việc kiểm tra dữ liệu được xử lý theo cách nào và với tần suất như thế nào nhằm giảm bớt việc phải ghi lại dữ liệu nhiều lần.
Phân tích dữ liệu
Chủ đề được nhắc tới nhiều nhất trong việc phân tích dữ liệu Big Data đó là học máy, đó là quá trình xây dựng nên những mô hình toán học để từ đó có thể giải quyết các bài toán khuyến nghị, phân cụm hay phân loại đối với những dữ liệu mới. Ví dụ như những bài toán đánh giá rủi ro, phát hiện lỗi, hay đơn giản như lọc thư rác. Tuy nhiên những tiến trình phân tích khác ngoài học máy như: xây dựng mối tương quan hay báo cáo dữ liệu vẫn còn rất phổ biến.
Tuy nhiên dù bằng phương pháp này hay phương pháp khác, cuối cùng những tiến trình biến đổi cũng như phân tích đó đều cần được thực hiện một cách tự động.
Luồng dữ liệu
Trước khi dữ liệu được xử lý một cách tự động ta cần kết hợp những công cụ và những tiến trình trong mỗi thành phần của hệ thống thành một luồng dữ liệu thống nhất. Có hai kiểu luồng dữ liệu như vậy là micro và macro.
Luồng dữ liệu kiểu micro cho phép thực hiện từng phần nhỏ trong toàn bộ quá trình xử lý lớn. Những công cụ phục vụ cho mục đích này có thể kể đến Morphlines, Crunch, hay Cascading. Morphlines thực hiện từng cụm tiến trình nhỏ lên mỗi bản ghi trong quá trình xử lý; trong khi đó Crunch với Cascading định nghĩa ra một lớp trừu tượng cho mỗi một vùng dữ liệu nhỏ. Tuy nhiên những tiến trình trong Crunch hay Cascading chưa thể kết hợp được với nhau để tạo ra một luồng tiến trình phức tạp hơn, điều mà có thể thực hiện dễ dàng đối với luồng dữ liệu kiểu macro.
Apache Oozie là một trong số những công cụ như vậy. Nó có khả năng định nghĩa một luồng tiến trình trong đó các tiến trình con có thể được thực hiện song song hay kết hợp một cách rất linh hoạt. Oozie còn hỗ trợ một thành phần đóng vai trò như một máy chủ sẽ kiểm soát và thống kê số liệu về những tiến trình đã đang và sẽ được thực thi. Đối với một tiến trình đơn lẻ hay đối với luồng dữ liệu kiểu micro, việc tiến trình sẽ chỉ được định nghĩa chứ không thể được thực thi một cách tự động, việc khởi chạy một tiến trình nào đó sẽ phải thực hiện một cách thủ công. Còn đối với Oozie, các luồng tiến trình có thể được thực thi tự động tại một thời điểm cụ thể với một tần suất cụ thể được định nghĩa ra bởi các coordinators của nó.
Sơ đồ dưới đây sẽ tổng kết lại một vài công cụ cũng như khái niệm có thể được sử dụng trong mỗi thành phần của luồng dữ liệu mà ta đã đề cập ở trên:
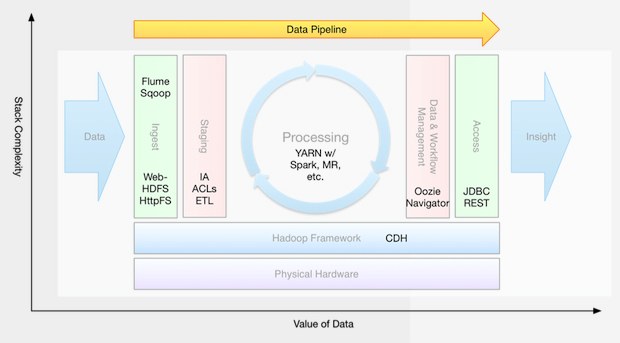 |
Hệ sinh thái phong phú của Hadoop hiện tại đã cung cấp hầu hết những công cụ để phục vụ cho việc xây dựng cũng như tự động hóa những hệ thống xử lý những luồng dữ liệu lớn. Bên cạnh đó, những công cụ này còn hỗ trợ hết sức đắc lực trong quá trình kiểm thử và triển khai hệ thống, thúc đẩy thương mại hóa sản phẩm. Tuy Hadoop ngày một lớn mạnh và phát triển nhưng tiềm năng của framework này vẫn còn chưa được khám phá hết, bởi vậy những kỹ sư Big Data giàu kinh nghiệm đang là những nhân tố vô cùng quan trọng và cần thiết trong việc thúc đẩy Hadoop phát triển và tiến xa hơn nữa trong lĩnh vực Big Data. Đây cũng là lí do để các chuyên gia công nghệ của FPT Software đầu tư nhiều hơn vào việc nghiên cứu sâu hơn và ứng dụng Hadoop vào quá trình phát triển các dự án thật.
Để có thêm thông tin, vui lòng truy cập: The-meanings-of-big-data-engineer-and-big-data-architecture
Vũ Thanh Hải
FSB, FPT Software









Ý kiến
()