
Thực tế, Google đã quan tâm và tiến hành công việc này bằng cách tự xây dựng cho họ một hệ thống riêng, với việc đảm bảo độ tin cậy khi lưu trữ và xử lý hàng petabytes dữ liệu. Việc này đã mang đến những cải tiến to lớn trong quá trình xử lý dữ liệu và được hầu hết chuyên gia, kỹ sư, lập trình viên tin tưởng cũng như chấp nhận một số giả thuyết hệ quả mà hệ thống đó đem lại.
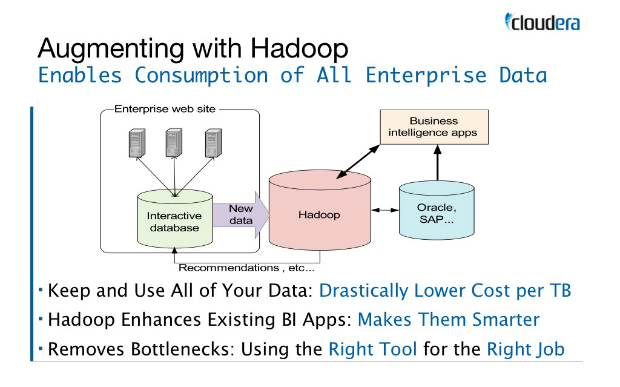 |
Tuy nhiên, mọi giả thuyết đều đã trở nên lạc hậu với sự xuất hiện của Hadoop. Để có thể hiểu được một phần sức mạnh của Hadoop, các lập trình viên có thể cân nhắc việc xem xét lại, thậm chí là quên đi một số giả thuyết cơ bản sau đây:
Giả thuyết thứ nhất: Chúng ta có thể tin cậy được vào phần cứng
Về lý thuyết, bạn có thể đầu tư vào việc xây dựng một hệ thống phần cứng với thời gian sử dụng liên tục từ lúc bắt đầu cho đến khi gặp lỗi (Mean Time To Failure - MTTF) đạt xấp xỉ với vòng đời thực tế của hệ thống đó. Nhưng với một lượng dữ liệu cực lớn (ví dụ dữ liệu web...) đòi hòi hàng trăm cũng như hàng nghìn máy chủ phục vụ việc lưu trữ và tính toán, thì thậm chí một hệ thống với MTTF là 4 năm cũng có thể gặp tới ít nhất 5 lỗi trong một tuần. Việc xem xét khả năng chịu lỗi vì thế trở nên cấp thiết, đòi phải phải được cung cấp thông qua phần mềm thay vì phần cứng để có thể thỏa mãn được tính tin cậy cũng như khả năng tính toán đối với lượng dữ liệu ngày càng khổng lồ như hiện nay.
Giả thuyết thứ hai: Các máy hoàn toàn độc lập với nhau
Nghĩa là không nên nghĩ rằng mỗi máy là một thành phần độc lập với một định danh riêng, vì nếu bạn muốn điều phối khả năng tính toán của nhiều máy tính một cách hợp lý thì rõ ràng các máy tính đó phải có khả năng giao tiếp với nhau. Tuy nhiên, từ những kết luận của giả thuyết thứ nhất, phần cứng chưa chắc đã đáng tin cậy, nên việc giao tiếp này phải được thực hiện một cách ngầm định thông qua phần mềm, nhằm tránh trường hợp gặp phải một vài vấn đề như xác minh tính tin cậy. Việc giao tiếp ngầm định như vậy sẽ cho phép hệ thống đảm bảo việc lưu trữ và tính toán một cách tin cậy mà không đòi hỏi lập trình viên phải xác minh quá trình giao tiếp.
Giả thuyết thứ ba: Dữ liệu có thể được lưu trữ chỉ trên một máy
Khi làm việc với một lượng dữ liệu lớn và ngày càng có xu hướng mở rộng mạnh mẽ thì việc sử dụng một ổ cứng với một bộ vi xử lý để phục vụ cho việc xử lý toàn bộ dữ liệu là điều bất khả thi. Điều này tất yếu dẫn đến việc thay đổi giả thuyết về cách thức lưu trữ và xử lý dữ liệu. Một tập dữ liệu lớn có thể được lưu trữ trên nhiều máy nhằm phục vụ quá trình tính toán song song, cũng như bất cứ máy nào cũng có thể xử lý bất kỳ thành phần nào trong tập dữ liệu đó. Việc xử lý có thể được thực hiện bằng cách mang thành phần tính toán (có thể hiểu là source code) đến nơi chứa dữ liệu thay vì mang dữ liệu đến nơi cần tính toán, việc này giúp tiết kiệm băng thông cực kỳ hiệu quả.
Như vậy, bằng việc bỏ qua một vài giả thuyết đã trở nên lạc hậu, bạn có thể một phần nào đó hiểu được các nguyên lý, các kiến trúc cũng như thành phần khiến cho Hadoop có thể cung cấp được một cơ sở hạ tầng đáng tin cậy kể cả khi vẫn sử dụng những hệ thống phần cứng thông thường.
Vũ Thanh Hải (FSB, FPT Software)








Ý kiến
()