
Bài viết này tập trung vào việc áp dụng phân tích dữ liệu lớn như thế nào cho sàn thương mại điện tử Sendo.vn.
Khuyến nghị sản phẩm
Hầu hết các trang thương mại điện tử đều có những khuyến nghị đi kèm như cho người dùng mua hoặc xem sản phẩm này thì sẽ mua hoặc xem sản phẩm tương tự nào.
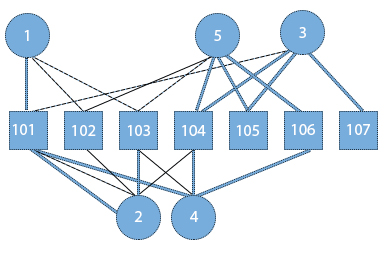
Trước đây, việc làm này thường được thực hiện bằng cách liệt kê các sản phẩm cùng loại. Hiện tại, thuật toán khuyến nghị sẽ giúp tìm ra các sản phẩm mà một khách hàng có thể quan tâm bằng cách tìm các sản phẩm mà những khách hàng tương tự khác qua đồ thị miêu tả (đường đậm: người dùng rất quan tâm đến sản phẩm, đường nét đứt: không quá thích nhưng có mối liên hệ đến sản phẩm đó). Bằng mắt thường ta có thể thấy người dùng 1 và 5 có sở thích giống nhau khi cùng thích sản phẩm 101 và hơi quan tâm đến 102 và 103. Người dùng 1 và 4 cũng khá tương đồng khi cùng thích 101 và hơi quan tâm đến 103. Trong khi đó, người dùng 4 và 5 rất thích 104 và 106, do đó có thể khuyến nghị 104, 106 cho người dùng 1.
 |
Thực tế khi số lượng người dùng và sản phẩm lên tới hàng triệu thì khối lượng dữ liệu là rất lớn. Hai thuật toán phố biến cho khuyến nghị là Frequent Pattern và Collaborative Filtering được tích hợp trong framework sẵn có như Mahout hay Spark MLLib. Spark MLLib đang nổi lên nhờ hỗ trợ các thuật toán mới và lập trình phân tán một cách đơn giản.
 |
 |
Để triển khai bài toán này cho Sendo.vn, các chuyên gia công nghệ đã xây dựng 2 module.
Module builder dùng để tiền xử lý dữ liệu thô sau đó áp dụng 2 thuật toán Frequent Pattern và Collaborative Filtering cho dữ liệu xem hàng và mua hàng. Kết quả trả ra được cache lại trên Redis và lưu xuống MongoDB.
Module Web API trả ra cho client, với mỗi yêu cầu từ client, hệ thống sẽ lấy dữ liệu cache sẵn từ Redis, trong trường hợp Redis bị lỗi thì có thể lấy từ MongoDB, với những dữ liệu chưa được tính sẵn (chưa tồn tại trong Redis và MongoDB) thì hệ thống sẽ nạp mô hình và tính toán tại chỗ.
Customer profiling
Việc xác định thông tin nhân khẩu học (demographic) về khách hàng là rất quan trọng trong thương mại điện tử để thực hiện các chiến lược marketing. Từ việc xem và mua sản phẩm chúng ta có thể đoán được giới tính, nơi sống, loại sản phẩm mà khách hàng có thể mua trong tương lai với độ chính xác chấp nhận được.
Dù không đăng nhập vào hệ thống thì khách hàng cũng cần tạo ra ID, ID này cần phải được duy trì dù người dùng có thoát khỏi trang, Apache Divolte là loại JavaScript có thể đáp ứng được nhu cầu này. Để dự đoán giới tính và sản phẩm có thể mua cần tập dữ liệu mẫu cho biết một người dùng có mức độ quan tâm đến sản phẩm cụ thể thường là nam hay nữ.
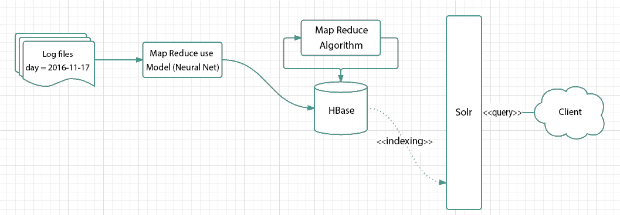
Về triển khai, dữ liệu log hàng ngày chạy qua Hadoop MapReduce sử dụng mô hình mạng neuron để tính ra giới tính và sản phẩm có thể mua trong tương lai, và dùng IP2Location để tính ra địa chỉ dựa trên IPAddress. Dữ liệu tính toán sẽ được lưu vào HBase, sau đó dữ liệu sẽ được tính toán từng phần dùng MapReduce. Sau đó dữ liệu từ HBase sẽ được indexing lên Solr để client có thể yêu cầu đến.
Quá trình triển khai bài toán này đã giúp cho việc tiếp cận và hiểu nhu cầu khách hàng của Sendo.vn phát triển vượt bậc. Hệ thống khuyến nghị người dùng không chỉ được ứng dụng cho thương mại điện tử mà còn góp phần tăng trải nghiệm người dùng trực tuyến trên nhiều lĩnh vực khác nhau như giải trí, truyền thông đa phương tiện, nhu cầu tìm kiếm thông tin hữu ích…
>> FPT là doanh nghiệp CNTT xuất sắc nhất ASEAN
Theo FPT Tech Insight










Ý kiến
()